Sarthak AhujaI am a Machine Learning Engineer at Alexa AI where I help build systems that predict and route user intents to appropriate Alexa actions. My work is centered around enabling scalable, safe and continuous end-to-end self-learning for intelligent decision making. Check out this recent paper from my team to learn more. Prior to Amazon, I was a Research Engineer in the Collaborative AI group at IBM Research. There I worked on nested belief modeling for enhancing multi-agent group collaboration in social decision making settings. I also contributed to the machine learning based requisition & candidate matching subsystem of IBM Watson Recruitment. tell me more Email / Resume / Google Scholar / GitHub |
 "be water my friend" |
Research InterestsI am interested in making Human-AI interactions more complete and aligned with human expectations within any given context. Whether it's an uncanny robot, a faceless voice assistant, or a conversational chatbot, I aim to make these systems address a user's explicit needs displaying an intuitive understanding of all sorts of implicit constraints imposed by their contextual setting; pursuing this goal keeps me interested in interdisciplinary research in language understanding, visual recognition, multi-agent systems and robotics. I have had wonderful collaborations with some amazing people over the years, some of which are listed below. |

|
DQA: Diagnostic Question Answering for IT SupportVishaal Kapoor, Mariam Dundua, Evren Yortucboylu, Sarthak Ahuja, Neda Kordjazi, Yiming Li, Vaibhavi Padala, Derek Ho, Jennifer Whitted, Rebecca Steinert Association of Computational Linguistics (ACL) 2026 paper / Enterprise IT support interactions are fundamentally diagnostic: effective resolution requires iterative evidence gathering from ambiguous user reports to identify an underlying root cause. While retrieval-augmented generation (RAG) provides grounding through historical cases, standard multi-turn RAG systems lack explicit diagnostic state and therefore struggle to accumulate evidence and resolve competing hypotheses across turns. We introduce DQA, a diagnostic question-answering framework that maintains persistent diagnostic state and aggregates retrieved cases at the level of root causes rather than individual documents. DQA combines conversational query rewriting, retrieval aggregation, and state-conditioned response generation to support systematic troubleshooting under enterprise latency and context constraints. We evaluate DQA on 150 anonymized enterprise IT support scenarios using a replay-based protocol. Averaged over three independent runs, DQA achieves a 78.7% success rate under a trajectory-level success criterion, compared to 41.3% for a multi-turn RAG baseline, while reducing average turns from 8.4 to 3.9. This improvement reflects the benefit of explicitly representing competing explanations and aggregating evidence across turns in unscripted troubleshooting. |

|
Improving Tool Retrieval by Leveraging Large Language Models for Query GenerationMohammad Kachuee, Sarthak Ahuja, Vaibhav Kumar, Puyang Xu, Derek Liu International Conference on Computational Linguistics (COLING) 2024 paper / Using tools by Large Language Models (LLMs) is a promising avenue to extend their reach beyond language or conversational settings. The number of tools can scale to thousands as they enable accessing sensory information, fetching updated factual knowledge, or taking actions in the real world. In such settings, in-context learning by providing a short list of relevant tools in the prompt is a viable approach. To retrieve relevant tools, various approaches have been suggested, ranging from simple frequency-based matching to dense embedding-based semantic retrieval. However, such approaches lack the contextual and common-sense understanding required to retrieve the right tools for complex user requests. Rather than increasing the complexity of the retrieval component itself, we propose leveraging LLM understanding to generate a retrieval query. Then, the generated query is embedded and used to find the most relevant tools via a nearest-neighbor search. We investigate three approaches for query generation: zero-shot prompting, supervised fine-tuning on tool descriptions, and alignment learning by iteratively optimizing a reward metric measuring retrieval performance. By conducting extensive experiments on a dataset covering complex and multi-tool scenarios, we show that leveraging LLMs for query generation improves the retrieval for in-domain (seen tools) and out-of-domain (unseen tools) settings. |

|
Scalable and Safe Remediation of Defective Actions in Self-Learning Conversational SystemsSarthak Ahuja, Mohammad Kachuee, Fatemeh Sheikholeslami, Weiqing Liu, Jaeyoung Do Association for Computational Linguistics (ACL) 2023 paper / Off-Policy reinforcement learning has been a driving force for the state-of-the-art conversational AIs leading to more natural human-agent interactions and improving the user satisfaction for goal-oriented agents. However, in large-scale commercial settings, it is often challenging to balance between policy improvements and experience continuity on the broad spectrum of applications handled by such system. In the literature, off-policy evaluation and guard-railing on aggregate statistics has been commonly used to address this problem. In this paper, we propose method for curating and leveraging high-precision samples sourced from historical regression incident reports to validate, safe-guard, and improve policies prior to the online deployment. We conducted extensive experiments using data from a real-world conversational system and actual regression incidents. The proposed method is currently deployed in our production system to protect customers against broken experiences and enable long-term policy improvements. |

|
Creating and using Triplet Representations to Assess Similarity between Job Description DocumentsDavid G. George, Sudhanshu S. Singh, Joydeep Mondal, Sarthak Ahuja, John A. Medicke, Amanda Klabzuba Granted Patent US11410130B2 2022 paper / One embodiment provides a method, including: receiving a requisition for a job position, the requisition having a plurality of recruiters, each having influence in selecting a candidate; generating a profile for an ideal candidate comprising (1) a plurality of attributes and (ii) weights corresponding to each of the attributes; receiving, for a plurality of candidates, profiles for each the candidates; comparing the profile of each of the plurality of candidates against the ideal candidate, using a distance method computation to determine the distance between the plurality of candidates and the ideal candidate based upon the weights; ranking the plurality of candidates and providing the ranking to each of the plurality of recruiters; receiving input from each of the plurality of recruiters that modifies the ranking, recalculating the weights of the attributes based upon the modified ranking, and modifying the ranking; and providing a final ranking of the plurality of candidates. |

|
Scalable and Robust Self-Learning for Skill Routing in Large-Scale Conversational AI SystemsMohammad Kachuee, Jinseok Nam, Sarthak Ahuja, Jin-Myung Won, Sungjin Lee North American Chapter of the Association for Computational Linguistics (NAACL) 2022 paper / Skill routing is an important component in large-scale conversational systems. In contrast to traditional rule-based skill routing, state-of-the-art systems use a model-based approach to enable natural conversations. To provide supervision signal required to train such models, ideas such as human annotation, replication of a rule-based system, relabeling based on user paraphrases, and bandit-based learning were suggested. However, these approaches: (a) do not scale in terms of the number of skills and skill on-boarding, (b) require a very costly expert annotation/rule-design, (c) introduce risks in the user experience with each model update. In this paper, we present a scalable self-learning approach to explore routing alternatives with- out causing abrupt policy changes that break the user experience, learn from the user inter- action, and incrementally improve the routing via frequent model refreshes. To enable such robust frequent model updates, we suggest a simple and effective approach that ensures controlled policy updates for individual domains, followed by an off-policy evaluation for making deployment decisions without any need for lengthy A/B experimentation. We conduct various offline and online A/B experiments on a commercial large-scale conversational system to demonstrate the effectiveness of the proposed method in real-world production settings. |

|
Virtual-Reality Based Interactive Audience SimulationSarthak Ahuja, Joydeep Mondal, Kushal Mukherjee, Sudhanshu Shekhar Singh Granted Patent US10970898B2 2021 paper / Methods, systems and computer program products for generating virtual reality (VR)-based interactive audience simulations are provided herein. A computer-implemented method includes determining one or more situational and location characteristics for a given performance by a user, generating a VR-based simulated audience for the given performance based at least in part on the determined situational and location characteristics, presenting the VR-based simulated audience to a user during the given performance utilizing a VR headset, utilizing one or more sensors to measure one or more aspects of the given performance before the VR-based simulated audience, and generating real-time feedback adjusting the VR-based simulated audience presented to the user utilizing the VR headset based at least in part on the measured aspects of the given performance. |

|
Examining the Effects of Anticipatory Robot Assistance on Human Decision MakingBenjamin A. Newman*, Abhijat Biswas*, Sarthak Ahuja, Siddharth Girdhar, Kris K. Kitani, Henny Admoni International Conference on Social Robotics (ICSR) 2020 paper / In this work, we investigate whether a robot’s anticipatory assistance can drive people to make choices different from those they would otherwise make. Such a study requires measuring intent, which itself could modify intent, resulting in an observer paradox. To combat this, we carefully designed an experiment to avoid this effect. We conducted a user study (N=99) in which participants completed a collaborative object retrieval task: users selected an object and a robot arm retrieved it for them. The robot predicted the user’s object selection from eye gaze in advance of their explicit selection, and then provided either collaborative anticipation (moving toward the predicted object), adversarial anticipation (moving away from the predicted object), or no anticipation (no movement, control condition). We found trends and participant comments suggesting people’s decision making changes in the presence of a robot anticipatory motion and this change differs depending on the robot’s anticipation strategy. |

|
Visual Assessment for Non-Disruptive Object ExtractionSarthak Ahuja Master's Thesis 2020 paper / Robots operating in human environments need to perform a variety of dexterous manipulation tasks on object arrangements that have complex physical support relationships, e.g. procuring utensils from a large pile of dishes, grabbing a bottle from a stuffed fridge, or fetching a book from a loaded shelf. The cost of a misjudged extraction in these situations can be very high (e.g., other objects falling) and therefore robots must be careful not to disturb other objects when executing manipulation skills. This requires robots to reason about the effect of their manipulation choices by accounting for the support relationships among objects in the scene. Humans do this in part by visually assessing the scene and using physics intuition to infer how likely it is that a particular object can be safely moved. Inspired by this human capability, we explore how robots can emulate similar vision-based physics intuition using deep learning based data-driven models. |

|
Learning Vision-Based Physics Intuition Models for Non-Disruptive Object ExtractionSarthak Ahuja, Henny Admoni, Aaron Steinfeld IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2020 paper / Robots operating in human environments must be careful, when executing their manipulation skills, not to disturb nearby objects. This requires robots to reason about the effect of their manipulation choices by accounting for the support relationships among objects in the scene. Humans do this in part by visually assessing their surroundings and using physics intuition for how likely it is that a particular object can be safely manipulated (i.e., cause no disruption in the rest of the scene). Existing work has shown that deep convolutional neural networks can learn intuitive physics over images generated in simulation and determine the stability of a scene in the real world. In this paper, we extend these physics intuition models to the task of assessing safe object extraction by conditioning the visual images on specific objects in the scene. Our results, in both simulation and real-world settings, show that with our proposed method, physics intuition models can be used to inform a robot of which objects can be safely extracted and from which direction to extract them. |

|
Dynamic Particle Allocation to Solve Interactive POMDP Models for Social Decision MakingRohith D Vallam, Sarthak Ahuja, Surya Shravan Kumar Sajja, Ritwik Chaudhuri, Rakesh R Pimplikar, Kushal Mukherjee, Gyana Parija, Ramasuri Narayanam International Conference on Autonomous Agents and Multiagent Systems (AAMAS) 2019 paper / In repeated social dilemma settings, such as repeated Public Goods Games (PGG), humans often come across a dilemma whether to contribute or not based on past contributions from others. In such settings, the decision taken by an agent/human actually depends not only on the belief the agent has about other agents and the environment, but also on their beliefs about others’ beliefs. To factor in these aspects, we propose a novel formulation of computational theory of mind (ToM) to model human behavior in a repeated PGG using interactive partially observable Markov decision processes (I-POMDPs). We also propose a dynamic particle allocation algorithm for different agents based on how well they could predict. Our results suggest that dynamic particle allocation based IPF for I-POMDPs is effective in modelling human behaviours in repeated social dilemma setting while utilizing computational resources in an effective manner. |

|
Benchmarking of a Novel POS Tagging Based Semantic Similarity Approach for Job Description Similarity ComputationJoydeep Mondal, Sarthak Ahuja, Kushal Mukherjee, Sudhanshu S. Singh, Gyana Parija European Semantic Web Conference (ESWC) 2018 paper / Most solutions providing hiring analytics involve mapping provided job descriptions to a standard job framework, thereby requiring computation of a document similarity score between two job descriptions. Finding semantic similarity between a pair of documents is a problem that is yet to be solved satisfactorily over all possible domains/contexts. Most document similarity calculation exercises require a large corpus of data for training the underlying models. In this paper we compare three methods of document similarity for job descriptions – topic modeling (LDA), doc2vec, and a novel part-of-speech tagging based document similarity (POSDC) calculation method. LDA and doc2vec require a large corpus of data to train, while POCDC exploits a domain specific property of descriptive documents (such as job descriptions) that enables us to compare two documents in isolation. POSDC method is based on an ”action-object-attribute” representation of documents, that allows meaningful comparisons. We use Standford Core NLP and NLTK Wordnet to do a multilevel semantic match between the actions and corresponding objects. We use sklearn for topic modeling and gensim for doc2vec. We compare the results from these three methods based on IBM Kenexa Talent frameworks job taxonomy |

|
#VisualHashtags- Visual Summarization of Social Media Events Using Mid-Level Visual ElementsSonal Goel, Sarthak Ahuja, A V Subramanyam, Ponnurangam Kumaraguru ACM Multimedia (ACMMM) 2017 paper / slides / In this paper we propose a methodology for visual event summarization by extracting mid-level visual elements from images associated with social media events on Twitter (#VisualHashtags). The key research question is Which elements can visually capture the essence of a viral event? hence explain its virality, and summarize it. Compared to the existing approaches of visual event summarization on social media data, we aim to discover #VisualHashtags, i.e., meaningful patches that can become the visual analog of a regular text hashtag that Twitter generates. Our algorithm incorporates a multi-stage filtering process and social popularity based ranking to discover mid-level visual elements, which overcomes the challenges faced by direct application of the existing methods. |

|
Similarity Computation Exploiting The Semantic And Syntactic Inherent Structure Among Job TitlesSarthak Ahuja, Joydeep Mondal, Sudhanshu S. Singh, David G. George International Conference on Service-Oriented Computing (ICSOC) 2017 paper / Solutions providing hiring analytics involve mapping company provided job descriptions to a standard job framework, thereby requiring computation of a similarity score between two jobs. Most systems doing so apply document similarity computation methods to all pairs of provided job descriptions. This approach can be computationally expensive and adversely impacted by the quality of the job descriptions which often include information not relevant to the job or candidate qualifications. We propose a method to narrow down pairs of job descriptions to be compared by comparing job titles first. The observation that each job title can be decomposed into three components, domain, function and attribute, forms the basis of our method. Our proposal focuses on training the machine learning models to identify these three components of any given job title. Next we do a semantic match between the three identified components, and use those match scores to create a composite similarity score between any two pair of job titles. The elegance of this solution lies in the fact that job titles are the most concise definition of the job and the resulting matches can easily be verified by human experts. Our results show that the approach provides extremely reliable results. |

|
Multi Level Clustering Technique Leveraging Expert InsightSudhanshu Singh, Ritwik Chaudhuri, Manu Kuchhal, Sarthak Ahuja, Gyana Parija Joint Statistical Meetings (JSM) 2017 paper / slides / State of the art clustering algorithms operate well on numeric data but for textual data rely on conversion to numeric representation. This conversion is done by adopting approaches like TFIDF, Word2Vec, etc. and require large amount of contextual data to do the learning. Such contextual data may not be always available for the given domain. We propose a novel algorithm that incorporates Subject Matter Experts’ (SME) inputs in lieu of contextual data to be able to do effective clustering of a mix of textual and numeric data. We leverage simple semantic rules provided by SMEs to do a multi-level iterative clustering that is executed on the Apache Spark Platform for accelerated outcome. The semantic rules are used to generate large number of small sized clusters which are qualitatively merged using the principles of Graph Colouring. We present the results from a Recruitment Process Benchmarking case study on data from multiple jobs. We applied the proposed technique to create suitable job categories for establishing benchmarks. This approach provides far more meaningful insights than traditional approach where benchmarks are calculated for all jobs put together. |

|
Applications of Modern SLAM Systems for Visual PositioningSarthak Ahuja Bachelor's Thesis 2016 Body mounted and vehicle cameras are becoming increasingly popular with the Internet overflowing with content from car dashboards, video bloggers, and even law enforcement officers. Analyzing these videos and getting more information about the anonymous entity has become a growing topic of study among vision groups across the world. A challenging task in this area of work is of localizing the anonymous entity in its surroundings without the use global systems such as GPS (which may prove to be unfeasible, unreliable or erratic in many situations). In this report we present a comprehensive study of Simultaneous Location and Mapping(SLAM) algorithms evaluating their application in detecting egomotion in egocentric videos, finally leading to the development of a Visual Positioning System for wearable and car dashboard cameras. |
Other ProjectsThese include filed patents and unpublished research work. |

|
VIGIL: Towards Edge-Extended Agentic AI for Enterprise IT SupportSarthak Ahuja*, Neda Kordjazi*, Evren Yortucboylu*, Vishaal Kapoor, Mariam Dundua, Yiming Li, Derek Ho, Vaibhavi Padala, Jennifer Whitted, Rebecca Steinert arxiv 2026 paper / Enterprise IT support is constrained by heterogeneous devices, evolving policies, and long-tail failure modes that are difficult to resolve centrally. We present VIGIL, an edge-extended agentic AI system that deploys desktop-resident agents to perform situated diagnosis, retrieval over enterprise knowledge, and policy-governed remediation directly on user devices with explicit consent and end-to-end observability. In a 10-week pilot of VIGIL’s operational loop on 100 resource-constrained endpoints, VIGIL reduces interaction rounds by 39%, achieves at least 4 times faster diagnosis, and supports self-service resolution in 82% of matched cases. Users report excellent usability, high trust, and low cognitive workload across four validated instruments, with qualitative feedback highlighting transparency as critical for trust. Notably, users rated the system higher when no historical matches were available, suggesting on-device diagnosis provides value independent of knowledge base coverage. This pilot establishes safety and observability foundations for fleet-wide continuous improvement. |
|
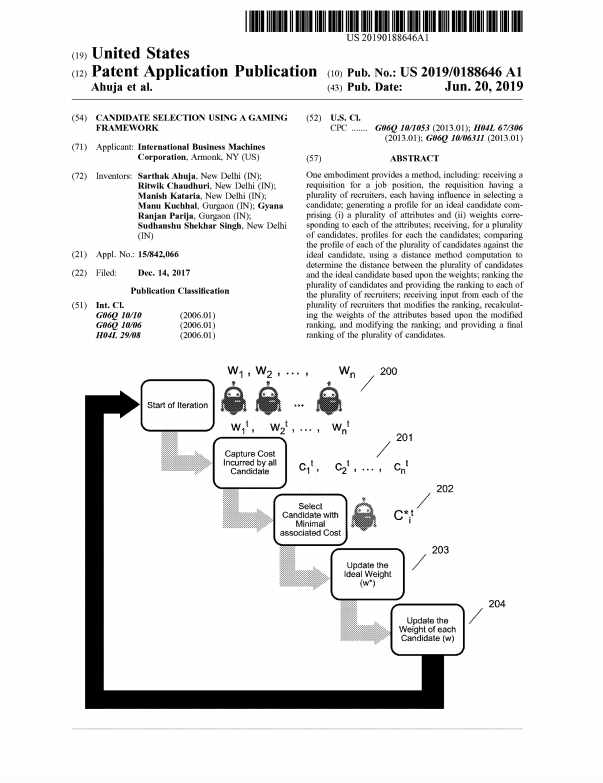
Candidate Selection using a Gaming FrameworkSarthak Ahuja, Ritwik Chaudhuri, Manish Kataria, Manu Kuchhal, Gyana R. Parija, Sudhanshu S. Singh Patent Application US15/842066 2019 paper / One embodiment provides a method, including: receiving arequisition for a job position, the requisition having a plurality of recruiters, each having influence in selecting a candidate; generating a profile for an ideal candidate comprising (1) a plurality of attributes and (ii) weights corre sponding to each of the attributes; receiving, for a plurality of candidates, profiles for each the candidates; comparing the profile of each of the plurality of candidates against the ideal candidate, using a distance method computation to determine the distance between the plurality of candidates and the ideal candidate based upon the weights; ranking the plurality of candidates and providing the ranking to each of the plurality of recruiters; receiving input from each of the plurality of recruiters that modifies the ranking, recalculating the weights of the attributes based upon the modified ranking, and modifying the ranking; and providing a final ranking of the plurality of candidates. |

|
Cogniculture- Towards a better Human-Machine Co-evolutionRakesh Pimplikar, Kushal Mukherjee, Gyana Parija, Ramasuri Naraynam, Rohith Vallam, Harith Vishvakarma, Sarthak Ahuja, Ritwik Chaudhuri, Joydeep Mondal, Manish Kataria arxiv 2017 paper / Research in Artificial Intelligence is breaking technology barriers every day. New algorithms and high performance computing are making things possible which we could only have imagined earlier. People in AI community have diverse set of opinions regarding the pros and cons of AI mimicking human behavior. Instead of worrying about AI advancements, we propose a novel idea of cognitive agents, including both human and machines, living together in a complex adaptive ecosystem, collaborating on human computation for producing essential social goods while promoting sustenance, survival and evolution of the agents’ life cycle. We highlight several research challenges and technology barriers in achieving this goal. We propose a governance mechanism around this ecosystem to ensure ethical behaviors of all cognitive agents. Along with a novel set of use-cases of Cogniculture, we discuss the road map ahead for this journey. |

|
Smartphone Audio Based Distress DetectionAnil Sharma, Sarthak Ahuja, Mayank Gautam, and Sanjit Kaul Independent Project 2016 paper / slides / dataset / We investigate an unobtrusive and 24×7 human distress detection and signaling system, Always Alert, that requires the smartphone, and not its human owner, to be on alert. The system leverages the microphone sensor, at least one of which is available on every phone, and assumes the availability of a data network. We propose a novel two-stage supervised learning framework, using support vector machines (SVMs), that executes on a user’s smartphone and monitors natural vocal expressions of fear — screaming and crying in our study — when a human being is in harm’s way. The challenge is to achieve a high distress detection rate while ensuring that the false alarm rate is a manageable overhead, while a typical smartphone user goes about living life as usual. We train the learning framework with carefully selected audio fingerprints of distress and of varied environmental contexts. Exploiting the time contiguous nature of false alarms further allows us to reduce the FAR. We show the feasibility of using our framework anytime and anywhere by testing it over many hours of audio fingerprints recorded by volunteers on their smartphones, as they went about their daily routines. We are able to achieve high distress detection rates at an average overhead that is equivalent to about 1 facebook post every 3 to 4 hours. |
Course ProjectsAuthor names are in alphabetical order. |

|
Informed Multi-Representation Multi-Heuristic A*Aditya Agarwal, Jay Patrikar, Sarthak Ahuja, Shivam Vats 16-782 Planning and Decision-making in Robotics 2020 paper / video / Generating motion plans for robots, like humanoids, with many degrees of freedom is a challenging problem because of the high-dimensionality of the resulting search space. To circumvent this, many researchers have made the observation that large parts of the solution plan are often much lower dimensional in nature. Some recent algorithms exploit this by either planning on a graph with adaptive dimensionality or leveraging a decoupling in the robot’s action space. Often, it is possible to gain more fine-grained information about the local dimensionality of the plan from any robot state to the goal which can then be used to inform search. In this work, we present a heuristic-search-based planning algorithm that admits such information as a prior in the form of lower dimensional manifolds (called representations) and a probabilistic mapping (conditioned on the world and the goal) from robot states to these representations. We train a Conditioned Variational Autoencoder (CVAE) for every representation and use them to compute the required probabilitic mapping. Us- ing this additional domain knowledge, our motion planner is able to generate high quality bounded-suboptimal plans. Experimentally, we validate the practicability and efficiency of our approach on the challenging 10 degree-of-freedom mobile manipulation domain. |

|
Semi-Supervised Stance Detection in TweetsAditya Agarwal, Sarthak Ahuja, Tanmay Agarwal 10-701 Machine Learning 2019 paper / poster / We implemented a heuristic-based semi-supervised learning approach, LDA2Vec (Moody CoNLL 2016) for stance detection that learns a coherent and informed embedding comparable to Para2Vec, concurrently bolstering interpretability of topics by creating representations similar to those in Latent Dirichlet Allocation. We conclude that adding unlabelled data vastly improves the performance of classifiers by ~6% for LDA and ~20% for Para2Vec. Overall Para2Vec seems to perform better than the Vanilla LDA. While we were able to obtain a similar quality of topics with LDA2Vec as compared to LDA, the generated embeddings did not reflect the expected classification quality compared to Para2Vec. |

|
Assistive Sketching and Animation Using Shape-Aware Moving Least Squares Deformations and Kinect based 2-D Mesh AnimationAditya Agarwal, Sarthak Ahuja 16-811 Math for Robotics and CSE333 Computer Graphics 2018 paper / code / At IIIT, I focused on animating a 2D mesh character and driving its actions through a kinect sensor. The system was implemented in Visual Studio and interacted with a kinect device to fetch the skeleton data captured in the form of coordinates. We then created our 2D mesh in QT and used these coordinates to mimic the obtained skeleton using forward kinematics. At CMU, I extended this project with Aditya and developed an end-to-end sketching platform which assists an artist to draw complex non-convex 2D characters; Implemented drawing tools using bezier curves, distance-transform based skeletonization, and shape-aware deformations (Sharma et al. SA 2015). |
|
Identifying Prolonged Narcotics UsersPrateekshit Pandey, Sarthak Ahuja CSE Pattern Recognition 2015 paper / dataset / World Drug Report by United Nations Office on Drugs and Crimes in 2014 clearly suggests that during the period 2003-2012 the increase in crime rates for possession for personal use worldwide was due to the increase in the total number of drug users, esp. cannabis and ATS (Amphetamine-Type Stimulants). Also with the recent improvements in the CCTV surveillance and the introduction of wearable video cameras for police officers in the United States and some other countries, a large amount of data is available for biometric analysis. We propose a system which can use the data of face images from such sources and identify faces possibly altered by prolonged narcotic drug usage. Experiments were conducted majorly on before-after drug mug-shot images made public by Multinomah Sheriff County Office. We use three different types of feature extraction techniques: HoG, Local Binary Patterns and Color Histogram, over which we apply a Support Vector Machine with different kernels to classify the face images. |

|
CoDrive: Crowd Souced Memory SharingChaitanya Kumar, Danish Goel, Manan Gakhar, Sarthak Ahuja CSE304 Practice of Programming 2015 paper / code / Often offline storage runs out on mobile devices, and the user then needs to store data either on cloud, or on external media. We propose a solution, wherein the user needn’t be concerned about the security of their data in the cloud, by simply storing it on a dedicated space on one of his trusted peers, at the luxury of a network. We have implemented an application that allows multiple users to share some space on each of their drives (offline storages). This is achieved by initially setting up a fixed amount of space on each user’s local drive, required for the purpose of the application. Once a user issues a request to his/her list of friends, it can be accepted for storing the user’s data. |

|
Multi-Sensor Data Fusion for Human Activity RecognizationAnchita Goel, Sarthak Ahuja CSE343 Machine Learning 2015 paper / code / dataset / Human activity recognition is a well known area of research in pervasive computing, which involves detecting activity of an individual by using various types of sensors. This finds great utility in the context of human-centric problems not only for purposes of tracking ones daily activities but also in monitoring activities of others - like the elderly, patrol officers, etc for purposes of health-care and security. With the growth of interest in AI, such a system can provide useful information to make the agent much more intelligent and aware about the user, thus giving a more personalized experience. Several technologies have been used to get estimates of a person’s activity like sensors found in smartphones(accelerometer, gyroscope, magnetometer etc.), egocentric cameras, other wearable sensors to measure vital signs like heart rate, respiration rate and skin temperature (apart from the same data provided by smartphones), worn on different parts of the body like chest, wrist, ankles, environment sensors to measure humidity, audio level, temperature etc. However, to the best of our knowledge we have come across no work where a fusion of these sensors and egocentric cameras has been put to use. In this paper we explore the suggested fusion of sensors and share the results obtained. Our fusion approach shows significant improvement over using both the chosen sensors independently. |

|
Multi-Agent Path Planning in Warehouse ButlersAnchita Goel, Sarthak Ahuja CSE643 Artificial Intelligence 2015 paper / code / The boom in the e-commerce industry has lead to the cropping up of a large number of warehouses all over the globe. Automating the delivery processes in these warehouses is a growing requirement to achieve a reduced cost in terms of manpower and increased efficiency in terms of time taken. Multi-agent path planning is a crucial aspect of this challenge. Naive approaches such as a complete A* over all combination of butlers and targets do not work in this case due to the huge statespace and neither does Local Repair A* where each butler selfishly moves toward the target and replans only on collision in a blindfolded manner. In this project we have implemented the MAPP algorithm and prepared a simulation bench to run any placement of walls, butlers and items, by hacking an opensource version of pacman. We evaluate multiple simulations of butlers and warehouse architectures, and detail our observations in this report. |
|
Design and source code from Jon Barron's website |